En el artículo anterior te conté qué son las unidades geoestadísticas, en especial los radios censales, y su potencial para trabajar con otras fuentes y formatos de datos utilizando Sistemas de Información Geográfica (SIG o GIS en inglés). Ahora, ¿cuáles son esas fuentes de datos y sus formatos? ¿Qué técnicas se pueden utilizar para ellos?
De la realidad territorial a modelos raster y vectoriales
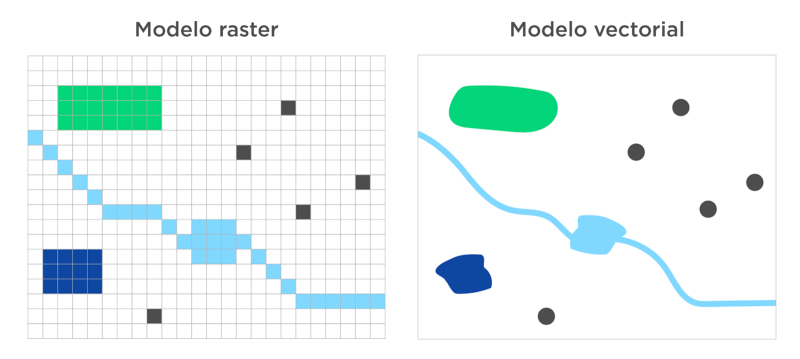
Los Sistemas de Información Geográfica modelan la realidad territorial para convertirla en datos geográficos. Por ejemplo, la ubicación de una escuela, se traduce en un punto con latitud y longitud que podemos visualizar en un mapa. Para modelar la realidad territorial, los SIG utilizan la representación raster o vectorial.
Créditos: Vanina Ogueta
El modelo raster consta de una matriz de celdas (o píxeles) organizadas en filas y columnas (o una cuadrícula) en la que cada celda contiene un valor que representa información, como la temperatura, por ejemplo. Las fotografías aéreas digitales o las imágenes de satelitales son ejemplos de este tipo de modelo.
Los modelos de representación vectorial modelizan los datos utilizando formas geométricas básicas: puntos, líneas y polígonos. Las geometrías son enriquecidas con los atributos temáticos de los fenómenos que representan. Por ejemplo, los cursos de agua, son modelizados a través de polilíneas (muchas líneas), y poseen atributos como el nombre y categoría, el régimen hídrico, el caudal anual, entre otros.1
Antes de continuar, recordemos que en el artículo anterior utilizamos los siguientes paquetes: tidyverse para manipular los datos, sf para trabajar con datos geográficos y leaflet para las visualizaciones dinámicas.
# Instalamos los paquetes si no están instalados en nuestras computadoras
# install.packages("tidyverse")
# install.packages("sf")
# install.packages("leaflet")
# Carga de los paquetes a utilizar
library(tidyverse)
library(sf)
library(leaflet)Para este artículo vamos a tomar de ejemplo al Partido de Morón en la Provincia de Buenos Aires. Por lo tanto, nuestra primer tarea es utilizar el archivo de radios censales de la Provincia de Buenos Aires y luego seleccionar únicamente los radios censales que pertenecen a Lomas de Zamora, es decir, sólo aquellos radios censales que comienzan con “06490”.
# Abriendo el shp
radios.buenos.aires <- st_read("../../static/files/Radios_2/Codgeo_Buenos_Aires_con_datos/",
layer = "Buenos_Aires_con_datos")## Reading layer `Buenos_Aires_con_datos' from data source `/Users/lauticantar/Google Drive/Github/lautarocantar/static/files/Radios_2/Codgeo_Buenos_Aires_con_datos' using driver `ESRI Shapefile'
## Simple feature collection with 19577 features and 8 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 3721440 ymin: 5452221 xmax: 4335413 ymax: 6305225
## epsg (SRID): NA
## proj4string: +proj=tmerc +lat_0=-90 +lon_0=-66 +k=1 +x_0=3500000 +y_0=0 +ellps=WGS84 +units=m +no_defsradios.buenos.aires <- st_transform(radios.buenos.aires, crs = 4326)
# Subseleccion de Radios Censales en Lomas de Zamora
rc.moron <- radios.buenos.aires %>% filter(str_detect(link, "06568"))Archivos planos
Estos archivos normalmente son una hoja de cálculo (Microsoft Excel, OpenOffice, etc) y suelen tener una columna que hace referencia a la unidad interoperable con la que estamos trabajando y nos permitiría unir el archivo a nuestro archivo geográfico. Por ejemplo, si nuestro se basa en los radios censales, habrá una columna que incluya el ID del radio censal. Para leer más sobre las guías interoperables, te recomiedo la Guía de identificación y uso de entidades interoperables de la Dirección Nacional de Datos Abiertos.
Continuando con nuestro ejemplo, el Instituto Nacional de Estadística y Censos (INDEC), por ejemplo, publica la cantidad de hogares que tienen conexión a red pública de cloacas agregado a nivel de radio censal en base al Censo 2010. Descarguemos el archivo y llamemosle cloacas.
# Definiendo la URL
cloacas.url <- "http://sig.planificacion.gob.ar/layers/download/lmarcos_hogares_red_de_cloacas/csv"
# Abriendo el dataset
cloacas <- read_csv(cloacas.url,
col_types = cols(
link = col_character(),
provincia = col_character(),
tot_hog10 = col_integer(),
Red_publica_de_agua = col_integer(),
A_camara_septica = col_integer(),
Solo_a_pozo_ciego = col_integer(),
A_hoyo_o_excavacion = col_integer(),
Total = col_integer(),
Sin_conexion_a_red = col_integer(),
Porcentaje_de_hogares_con_conexion_a_red = col_double(),
Porcentaje_de_hogares_sin_conexion_a_red = col_double())
)
# Editando el dataset
cloacas <- cloacas %>%
select(link, provincia, tot_hog10, Red_publica_de_agua, A_camara_septica, Solo_a_pozo_ciego,
A_hoyo_o_excavacion, Sin_conexion_a_red) %>%
rename(Radio_Censal = link,
Provincia = provincia,
Cantidad_hogares = tot_hog10,
cloacas_conexion_red_publica = Red_publica_de_agua,
cloacas_conexion_camara_septica = A_camara_septica,
cloacas_conexion_pozo_ciego = Solo_a_pozo_ciego,
cloacas_conexion_hoyo_o_excavacion = A_hoyo_o_excavacion,
cloacas_total_sin_conexion_a_red = Sin_conexion_a_red) %>%
mutate(cloacas_pje_hogares_red = cloacas_conexion_red_publica/Cantidad_hogares,
Radio_Censal = case_when(nchar(Radio_Censal) == 8 ~ paste0("0", Radio_Censal),
TRUE ~ Radio_Censal))Dado que el archivo contiene la columna “Radios_Censales” y nuestro archivo de radios censales también, la integración es un simple problema de integración entre ambos archivos.
Antes de hacer la unión entre el dataset cloacas y el dataset de rc.moron, vamos a hacer una subselección para trabajar únicamente con los datos del Municipio de Morón. Nuevamente vamos a seleccionar aquellos radios censales que comiencen con los valores “06568”. En Morón hay 357 radios censales y vamos a trabajar únicamente con la variable cloacas_pje_hogares_red.
# Subseleccion de # Subseleccion de Radios Censales en Lomas de Zamora
cloacas.moron <- cloacas %>% filter(str_detect(Radio_Censal, "06568"))Ahora si, podemos hacer la unión de ambas bases de datos:
# Cambiando el tipo de la variable "Link" para hacer la union de los datos
rc.moron$link <- as.character(rc.moron$link)
# Union de ambas bases de datos
rc.moron <- rc.moron %>%
left_join(cloacas.moron %>%
select(Radio_Censal, cloacas_pje_hogares_red),
by = c("link" = "Radio_Censal"))Perfecto, ya tenemos la unión de ambos dataset y podemos graficarlo. Pero antes vamos a explorar cómo están distribuidos los datos del porcentaje de los hogares de cada Radio Censal que tienen conexión a la red de cloacas pública. Para eso veamos los cuantiles de cloacas_pje_hogares_red.
cuartiles <- quantile(rc.moron$cloacas_pje_hogares_red)
cuartiles## 0% 25% 50% 75% 100%
## 0.00000000 0.02403846 0.86413043 0.98437500 1.00000000Morón es un departamento enteramente urbano, en el cual la mitad de los radios censales tiene menos del 67% de las viviendas conectadas a la red pública de cloacas. Por lo tanto, para graficarlo vamos a generar una nueva variable que clasifique a los radios censales en 4 categorías diferentes, una categoría para cada cuartil.
# Nueva Variable
rc.moron <- rc.moron %>%
mutate(cloacas.pje = case_when(.$cloacas_pje_hogares_red <= cuartiles[[2]] ~ 1,
.$cloacas_pje_hogares_red <= cuartiles[[3]] ~ 2,
.$cloacas_pje_hogares_red <= cuartiles[[4]] ~ 3,
.$cloacas_pje_hogares_red > cuartiles[[4]] ~ 4))Vamos a crear una paleta de colores para cada una de las categorías para poder graficarlas y que se entienda nuestro hermoso gráfico.
# Cambiando los nombres de las variables creadas anteriormente
cuartiles.colores <- factor(c(1,2,3,4),
labels = c("0-24.99%", "25-49.99%",
"50-74.99%", "75-100%"))Creando la paleta de colores
colors <- c("#e3f2fd", "#64b5f6", "#1e88e5", "#0d47a1")
binpal <- colorBin(colors, rc.moron$cloacas.pje, 4, pretty = FALSE)
Color_Assets <- colorFactor(colors, levels = cuartiles.colores, ordered=TRUE)Antes de hacer el mapa, creemos un nuevo shapefile que tenga el contorno del Partido de Morón. De esta forma nuestros mapas van a quedar mejor.
moron <- rc.moron %>% mutate(unos = 1) %>% summarise(suma = sum(unos))Ahora si, a hacer el mapa!
# Mapeando
leaflet() %>%
addTiles() %>%
addProviderTiles("CartoDB.Positron") %>%
# Mapeando los poligonos de Lomas de Zamora
addPolygons(data = rc.moron,
color = ~binpal(cloacas.pje), weight = 1, smoothFactor = 1,
stroke = FALSE, fillOpacity = 0.5) %>%
addPolygons(data = moron, fill = NA, color = "black", fillOpacity = NA) %>%
addLegend("bottomright", pal = Color_Assets, values = cuartiles.colores,
title = "Porcentaje de Acceso <br>a la Red Pública",
opacity = 1)Puntos
Cada lugar, cada movimiento que hacemos tiene una referencia en el espacio, una latitud y longitud asociada, que se puede referenciar en un mapa. Con esa latitud y longitud, podemos hacer varias operaciones para expresarlas agregadamente en terminos de radios censales. Una de esas operaciones es la intersección entre los polígonos de los radios censales y los puntos que estamos interesados. De esta forma, todos los puntos que caigan dentro de dicho polígono serán asignados a dicho radio censal.
Para nuestro ejemplo vamos a trabajar con un set de datos de escuelas primarias estatales. En el Partido de Morón hay 50 escuelas primarias estatales y, al visualizarlas en un mapa, vemos que están distribuidas a lo largo de todo el partido.
# Definiendo la URL
escuelas <- st_read("../../static/files/Radios_2/escuelas_moron/escuelas_moron.shp")## Reading layer `escuelas_moron' from data source `/Users/lauticantar/Google Drive/Github/lautarocantar/static/files/Radios_2/escuelas_moron/escuelas_moron.shp' using driver `ESRI Shapefile'
## Simple feature collection with 50 features and 49 fields
## geometry type: POINT
## dimension: XY
## bbox: xmin: -58.66164 ymin: -34.69885 xmax: -58.56455 ymax: -34.60672
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs# Seleccionando únicamente las escuelas de Morón
escuelas_moron <- escuelas %>% filter(str_detect(cod_loc, "06568"))
# Mapeando las escuelas
leaflet() %>%
addTiles() %>%
addProviderTiles("CartoDB.Positron") %>%
addPolygons(data = rc.moron,
color = "grey",
weight = 1,
smoothFactor = 0.5,
opacity = 1) %>%
addCircleMarkers(data = escuelas_moron,
radius = 1,
color = "#0d48a1",
opacity = 1) %>%
addPolygons(data = moron, fill = NA, color = "black", fillOpacity = NA)Antes de hacer la intersección, debemos considerar que ambos archivos deben tener la misma proyección:
# Controlando que tengan la misma proyeccion
st_crs(rc.moron)## Coordinate Reference System:
## EPSG: 4326
## proj4string: "+proj=longlat +datum=WGS84 +no_defs"st_crs(escuelas_moron)## Coordinate Reference System:
## EPSG: 4326
## proj4string: "+proj=longlat +datum=WGS84 +no_defs"Dado que ambos archivos geográficos tienen la misma proyección, hagamos la intersección! Para eso vamos a utiizar la función st_intersection del paquete sf. Una aclaración: los dos archivos tienen que ser archivos geográficos. Nuestra intersección se va a llamar inter.escuelas.
# Creando la interseccion
inter.escuelas <- st_intersection(rc.moron, escuelas_moron)
inter.escuelas <- inter.escuelas %>%
group_by(link) %>%
tally() %>%
as.data.frame()Hagamos ahora la unión con el archivo rc.moron.
rc.moron <- rc.moron %>%
left_join(inter.escuelas %>%
select(link, n))
rc.moron <- rc.moron %>%
mutate(n = as.numeric(n)) %>%
mutate(n = case_when(is.na(n) ~ 0,
TRUE ~ n))
# Definimos la paleta de colores
pal <- colorNumeric(
palette = "Blues",
domain = rc.moron$n)
# Hacemos el mapa
leaflet() %>%
addTiles() %>%
addProviderTiles("CartoDB.Positron") %>%
# Mapeando los polígonos de Lomas de Zamora
addPolygons(data = rc.moron,
color = ~pal(n),
weight = 1,
smoothFactor = 1,
stroke = 0.1,
fillOpacity = 0.75) %>%
addPolygons(data = moron, fill = NA, color = "black", fillOpacity = NA)Polígonos
Una plaza puede ser representada con un cuadrado, mientras que una rotonda puede representarse con un círculo. A estas formas geométricas las denominamos polígonos y son de gran utilidad para representar, por ejemplo, la zonificación de una ciudad: qué áreas están destinadas a comercios, viviendas o industrias. Nosotros vamos a utilizar como ejemplo un set de datos de barrios populares de la Argentina, el cual surge un relevamiento realizado en diciembre 2016, por diversas organizaciones sociales y Jefatura de Gabinete de Ministros.
La definición de un radio censal responde a una construcción metodológica estadística mientras que la constitución de un barrio popular responde a otra lógica, una signada por la necesidad. Por lo tanto, un radio censal puede estar atravesado por uno o más barrios populares. Una estrategia para trabajar con este tipo de situaciones es utilizar nuevamente la operación intersección entre polígonos. Podemos calcular qué porcentaje de superposición existe entre ambos polígonos.
# Abriendo el shp
barrios.populares <- st_read("../../static/files/Radios_2/barrios-populares/barrios-populares.shp")## Reading layer `barrios-populares' from data source `/Users/lauticantar/Google Drive/Github/lautarocantar/static/files/Radios_2/barrios-populares/barrios-populares.shp' using driver `ESRI Shapefile'
## Simple feature collection with 4228 features and 5 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -71.56234 ymin: -54.82007 xmax: -54.01357 ymax: -22.04006
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defsnames(st_geometry(barrios.populares)) = NULL
# Filtrando para Buenos Aires
barrios.populares <- barrios.populares %>% filter(departamen == "MORON")Descargando y abriendo el archivo observamos que fueron relevados 4228 barrios populares en el país. Sin embargo nosotros vamos a trabajar únicamente con los 11 que se encuentran en Morón.
leaflet() %>%
addTiles() %>%
addProviderTiles("CartoDB.Positron") %>%
# Mapeando los polígonos de Lomas de Zamora
addPolygons(data = rc.moron,
color = "#d1d1d1", weight = 1, smoothFactor = 1,
stroke = 0.1, fillOpacity = 0.5) %>%
# Mapeando los polígonos de los Barrios Populares
addPolygons(data = barrios.populares,
color = "#0d47a1", weight = 1, smoothFactor = 1,
stroke = 0.1, fillOpacity = 0.5) %>%
addPolygons(data = moron, fill = NA, color = "black", fillOpacity = NA)Una forma de integrar ambas bases de datos es calcular que porcentaje de un radio censal está ocupada por un barrio popular. Para esto, primero tenemos que calcular el área de cada radio censal y de cada barrio popular.
# Calculando el area en KM2 de cada unos de los poligonos
rc.moron$Area_RC <- st_area(rc.moron)
barrios.populares$Area_BP <- st_area(barrios.populares)Antes de hacer la intersección entre ambos archivos, nos tenemos que asegurar que tengan la misma proyección.
# Controlando que tengan la misma proyeccion
st_crs(rc.moron)## Coordinate Reference System:
## EPSG: 4326
## proj4string: "+proj=longlat +datum=WGS84 +no_defs"st_crs(barrios.populares)## Coordinate Reference System:
## EPSG: 4326
## proj4string: "+proj=longlat +datum=WGS84 +no_defs"Nuevamente, vamos a hacer intersección entre ambos archivos y ahora la llamaremos int. Luego vamos a calcular el área (en m2) de la superposición.
# Creando la interseccion
int <- st_intersection(rc.moron, barrios.populares)
# Calculando el area de la superposicion
int$area_int <- st_area(int)El paso siguiente es calcular el porcentaje de la superpocisión del área, la cual no puede ser mayor a 100.
# Calculando el porcentaje del RC que es un BP
int$Pje_BP_en_RC <- (int$area_int/int$Area_RC)*100
# Explorando los resultados
summary(int$Pje_BP_en_RC)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.5937 1.0885 3.8459 9.8467 10.6273 51.9559Por último hacer un par de operaciones para acomodar los datos y adjuntarnos a nuestro dataset rc.moron.
# Operaciones intermedias
int.2 <- as.data.frame(int) %>% group_by(link) %>% summarise(Pje_Total_BP_en_RC = sum(Pje_BP_en_RC))
int.2$Pje_Total_BP_en_RC <- round(int.2$Pje_Total_BP_en_RC, 2)
# Adjuntarlo al nuestro dataset original
rc.moron <- rc.moron %>% left_join(int.2)
rc.moron$Pje_Total_BP_en_RC <- as.numeric(rc.moron$Pje_Total_BP_en_RC)
rc.moron <- rc.moron %>%
mutate(Pje_Total_BP_en_RC = case_when(is.na(Pje_Total_BP_en_RC) ~ 0,
TRUE ~ Pje_Total_BP_en_RC))Ahora si graficamos aquellos radios censales que tengan Barrios Populares:
pal <- colorNumeric(
palette = "Blues",
domain = rc.moron$Pje_Total_BP_en_RC)
leaflet() %>%
addTiles() %>%
addProviderTiles("CartoDB.Positron") %>%
# Mapeando los polígonos de Lomas de Zamora
addPolygons(data = rc.moron,
color = ~pal(Pje_Total_BP_en_RC), weight = 1, smoothFactor = 1,
stroke = FALSE, fillOpacity = 0.5) %>%
addPolygons(data = moron, fill = NA, color = "black", fillOpacity = NA) %>%
addLegend("bottomright", pal = pal, values = rc.moron$Pje_Total_BP_en_RC,
title = "Porcentaje de Barrio Popular<br>en Radios Censales",
opacity = 1)Este es el segundo de una serie de artículos que buscan introducir la temática de datos geoespaciales a investigaciones. A su vez, cada uno de los artículos, tiene un tutorial sobre cómo trabajar estos temas en R. Para una versión conceptual y sin código en este mismo artículo, puedes encontrarla en Medium.
Si te sirvió este artículo, te invito a compartirlo!
Para más información, te invito a leer la página del Instituto Geográfico Nacional. En adelante vamos a trabajar con modelos de representación vectorial.↩